I’ve recently been working to add more details to my local area on the Open Street Map. To do this, I’ve been using a service called ‘Rapid‘, which uses machine learning to offer some assistance which can help speed things up.
The Open Street Map (OSM) is an open mapping dataset. Where google maps is closed, owned by google, the open street map is owned by a non-profit and the data is free to use. If you’ve never come across it before, think of it like a Wikipedia for maps. OSM edits can be made with various applications, the easiest to start with is called id. You can try it yourself by visiting https://www.openstreetmap.org/ and pressing the edit button.
Editing the map accurately can be finnicky and requires a fair bit of practice. Learning how to use datasets like GPS traces (user-uploaded recordings of movements using GPS data) and government sources like cadastral parcels (registers of land ownership), as well as aligning with street-level, aerial, and satellite imagery are key parts of setting out the base land areas and buildings that the rest of the map is built on top of. Without these, it becomes much more difficult to add addresses, shops, restaurants, and all the data that people want to use on a day to day business.
One of the more tedious tasks is adding buildings. In some parts of the world, like cities, it can be quite easy because everything is tall buildings arranged in a square grid with flats on top and shops on the bottom. In suburban and rural areas, however things are more difficult. Especially in places like Scotland where you have everything from centuries old villages that have grown haphazardly to modern New Towns that took, shall we politely say, experimental approaches to building neighbourhoods. Building shapes can be irregular, difficult to define, and occasionally require local knowledge of how they are arranged.
This is where Machine Learning (ML) can come in handy. For regular shaped buildings, a statistical algorithm can scan across aerial and satellite imagery to spot square shapes and pre-populate the edges of areas that a map editor can use to add buildings to the map. This gives me more time to focus on the interesting edge cases. I have found that it does work well in some cases, and does poorly in others. For that reason, I refuse to call it artificial intelligence, because it is not in a state where it is ready to be used for totally automated editing.
When you have sparse regular buildings like detached, semi-detached, and terraced houses, it can pick up on them quite well. Some clear roads can also be identified.
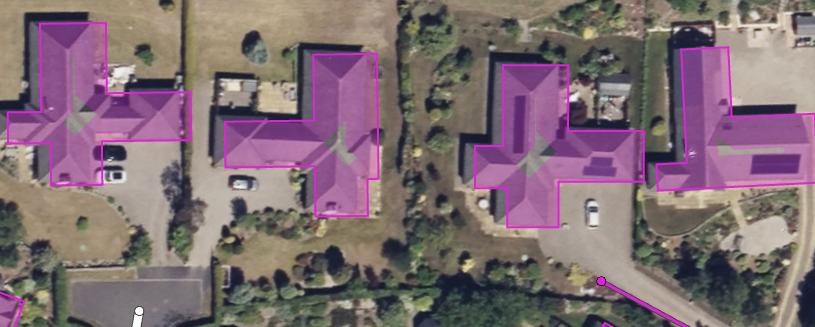
The service struggles with buildings as they get more complex, however. Gardens that are not just empty lawns. Sometimes things like adjoining garages, tight corners, extensions can result in inaccurate suggestions.

In almost every case, there are alignment issues. I am not sure if this is difficulties with the algorithm being confused by shadows or the angle of photography, making it difficult to identify the right height or base of a building. But almost every building footprint suggestion I have used needed some sort of realignment to match correct GPS or cadastral data.
Some shapes and patterns, like greenhouses, seem to confuse the algorithm so much that it becomes unusable.

There are some improvements I would like to see in the future:
- More training on non-US data. From the source, it seems that most data comes from the US. US-build neighbourhoods are going to be totally different to areas from Europe. More diverse data would result in much more useful models worldwide.
- Semi-detached houses and terraced houses currently appear as a single area. But by analysing data like garden fences, roofing, it is possible to identify where they should be listed as separate buildings.
- It should be possible to suggest some building types. Tall buildings are likely flats, long rectangles are likely terraced rows, and underlying data areas like “farmland” or “residential” should hint at whether a building is residential or commercial.
- I sometimes see building footprints overlapping different areas. It is obvious for a human that you can’t have two areas overlapping each other. I guess the models are treating each building in isolation. Some additional checks for collisions would help the suggestions be more useful.
In general though, I am finding the ML models (offered under open license by Microsoft and Facebook) quite useful. For most urban environments, the suggested building footprints and roads are accurate enough that it frees me up to think about how the map needs to be laid out accurately, rather than having to manually add each and every building.
Interesting read, great work on ML models 👍
Very interesting post.
As one who has worked in mapping I found it very interesting to read and thinking of the mappers who sat for the day generating maps from areal photos. I have OSM because of an interest but as I seldom get out anymore and fewer and fewer new buildings are being built… well interest fades. Also in Canada not all mapping is Open Source and there is no way to export to OSM. Various districts have regarded maps as a source of income and that mentality still exists. Gradually it is changing.